mysql
maven
newman
百度
react.js
阿克曼
flex
turtle
r语言
论文写作
AI作画
flume
目录和文件管理
无线控制器
cisp题库
shiro
CalBioreagents
社交媒体
个人博客
设置默认浏览器
rdd
2024/4/12 20:42:16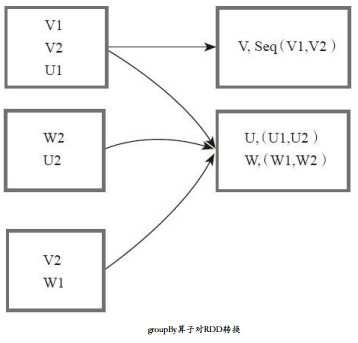
RDD-Transformation——groupByKey
简介
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
该函数用于将 RDD[K,V] 中每个K对应的V值,合并到一个集合 Iterable[V] 中…

RDD Transformation——reduceByKey
简介
def reduceByKey(func: (V, V) > V): RDD[(K, V)]def reduceByKey(func: (V, V) > V, numPartitions: Int): RDD[(K, V)]def reduceByKey(partitioner: Partitioner, func: (V, V) > V): RDD[(K, V)]
该函数用于将RDD[K,V]中每个K对应的V值根据映射函数来运算。…
spark 函数(python)
RDD的概念 RDD是Spark中的抽象数据结构类型,任何数据在Spark中都被表示为RDD。从编程的角度来看,RDD可以简单看成是一个数组。和普通数组的区别是,RDD中的数据是分区存储的,这样不同分区的数据就可以分布在不同的机器上…

Spark combineByKey 参数含义与性能测试
一.引言:
combineByKey 是一个泛型函数,使用一组自定义的聚合函数组合每个键的元素,常见的聚合函数groupByKey就是以combineByKey为原型扩展的,更多地细节可以参考 combineByKeyWithClassTag。 二.源码与参数含义:
/*
Generic f…
Spark-Core核心算子
文章目录 一、数据源获取1、从集合中获取2、从外部存储系统创建3、从其它RDD中创建4、分区规则—load数据时 二、转换算子(Transformation)1、Value类型1.1 map()_1.2 mapPartitions()1.3 mapPartitionsWithIndex(不常用)1.4 filterMap()_扁平化(合并流)…
Spark学习(二)
RDD(resilient distributed dataset)
RDD概念
RDD(Resilient Distributed Dataset)是一个弹性分布式数据集,是SPark提供的抽象的弹性分布式数据集(RDD),它是可以并行操作的跨集群节点的元素集合。RDDs是从…
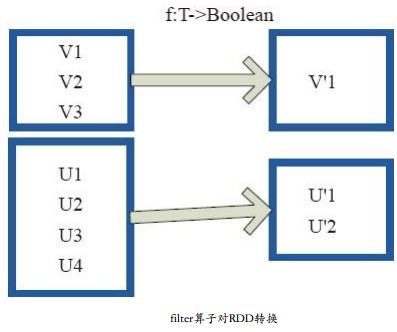
RDD-Transformation——filter
原理图
filter的功能是对元素进行过滤,对每个元素应用f函数,返回值为true的元素在RDD中保留,返回为false的将过滤掉。 内部实现相当于生成FilteredRDD(this,sc.clean(f))。 图中,每个方框代表一个RDD分区。 T可以是任…
Spark面试整理-Spark中的转换和行动操作有哪些?
在Apache Spark中,操作主要分为两类:转换(Transformations)和行动(Actions)。这些操作定义了如何处理RDD(弹性分布式数据集)。 转换操作(Transformations) 转换操作是应用于RDD的操作,它们创建一个新的RDD。转换操作是懒惰的,也就是说,它们不会立即计算结果,而是…

Spark----RDD(弹性分布式数据集)
RDD 文章目录 RDDRDD是什么?为什么需要RDD?RDD的五大属性WordCount中的RDD的五大属性如何创建RDD?RDD的操作两种基本算子/操作/方法/API分区操作重分区操作聚合操作四个有key函数的区别 关联操作排序操作 RDD的缓存/持久化cache和persistchec…
SparkCore基础解析(二)
1、 RDD概述
1.1 什么是RDD
RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
1.2 RDD的属性 1)一组分区&#x…
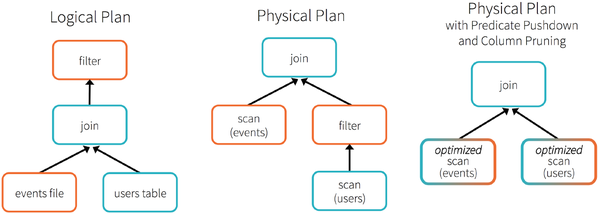
RDD 、 DataFrame 和 DataSet 详解
RDD、DataFrame和DataSet的区别 RDD、DataFrame和DataSet是容易产生混淆的概念,必须对其相互之间对比,才可以知道其中异同。 RDD和DataFrame RDD-DataFrame上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但…

尚硅谷大数据技术Spark教程-笔记04【SparkCore(核心编程,RDD-行动算子-序列化-依赖关系-持久化-分区器-文件读取与保存)】
视频地址:尚硅谷大数据Spark教程从入门到精通_哔哩哔哩_bilibili 尚硅谷大数据技术Spark教程-笔记01【Spark(概述、快速上手、运行环境、运行架构)】尚硅谷大数据技术Spark教程-笔记02【SparkCore(核心编程,RDD-核心属…
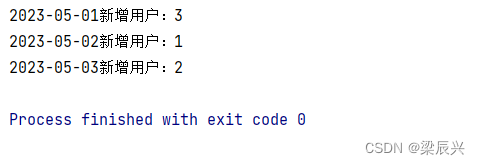
Spark RDD统计每日新增用户
文章目录 一,提出任务二,实现思路三,准备工作1、在本地创建用户文件2、将用户文件上传到HDFS指定位置 四,完成任务1、在Spark Shell里完成任务(1)读取文件,得到RDD(2)倒排…
Spark RDD | 常用函数讲解与代码实践
😄 因为spark里用的就是RDD数据结构来存储数据,所以对数据处理离不开RDD的各种函数操作咯!这一节就跟着梁云大佬打卡下如何处理RDD。【下面章节有🔥的是用的比较多的函数】 文章目录 0、初始化pyspark环境与driver介绍0.1、初始化…

2023年Spark大数据处理讲课笔记
文章目录一、Scala语言基础二、Spark基础三、Spark RDD弹性分布式数据集一、Scala语言基础
Spark大数据处理讲课笔记1.1 搭建Scala开发环境Spark大数据处理讲课笔记1.2 Scala变量与数据类型Spark大数据处理讲课笔记1.3 使用Scala集成开发环境Spark大数据处理讲课笔记1.4 掌握S…

【Spark】深入理解巧妙的RDD设计
文章目录相关概念Spark架构设计Spark基本运行流程RDD简介与知识点RDD简单执行过程RDD依赖关系及Stage的划分相关概念
RDD:Resillient Distributed Dataset,弹性分布式数据集,是分布式内存的一个抽象概念,提供了一种高度受限的共享…
spark学习——RDD概念
目录RDD定义RDD特性RDD定义 RDD(Resilient Distributed Dataset)是弹性分布式数据集,是spark中最基本的数据抽象,代表一个不可变、可分区、可并行计算的数据集合。 不可变:可认为RDD是分布式的列表(list)或数组&am…

Apache Spark基础及架构
文章目录一.为什么使用Spark二.Spark简介1.发展历程2.Spark优势3.Spark技术栈4.Spark环境部署5.Spark初体验6.Spark架构设计7.Spark架构核心组件8.Spark API三.核心API:RDD1.RDD概念2.RDD与DAG3.RDD的五大特性4.RDD编程流程5.RDD创建6.RDD分区与RDD的操作7.RDD转换算子8.RDD动作…

Spark 中 RDD 的详细介绍
RDD ---弹性分布式数据集 RDD概述
RDD论文
中文版 : http://spark.apachecn.org/paper/zh/spark-rdd.html
RDD产生背景
为了解决开发人员能在大规模的集群中以一种容错的方式进行内存计算,提出了 RDD 的概念,而当前的很多框架对迭代式算法场景与交互…

大数据:pyspark模块,spark core的RDD,RDD是弹性分布式数据抽象对象,RDD五大特性,wordcount案例展示RDD
大数据:pyspark模块
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle,尤其sql…

Spark学习笔记(五):Spark运行模式原理
基本概念
RDD:是Resillient Distributed Dataset (弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型DAG:是Directed Acyclic Graph (有向无环图)的简称,反映RDD之间的依赖关系E…
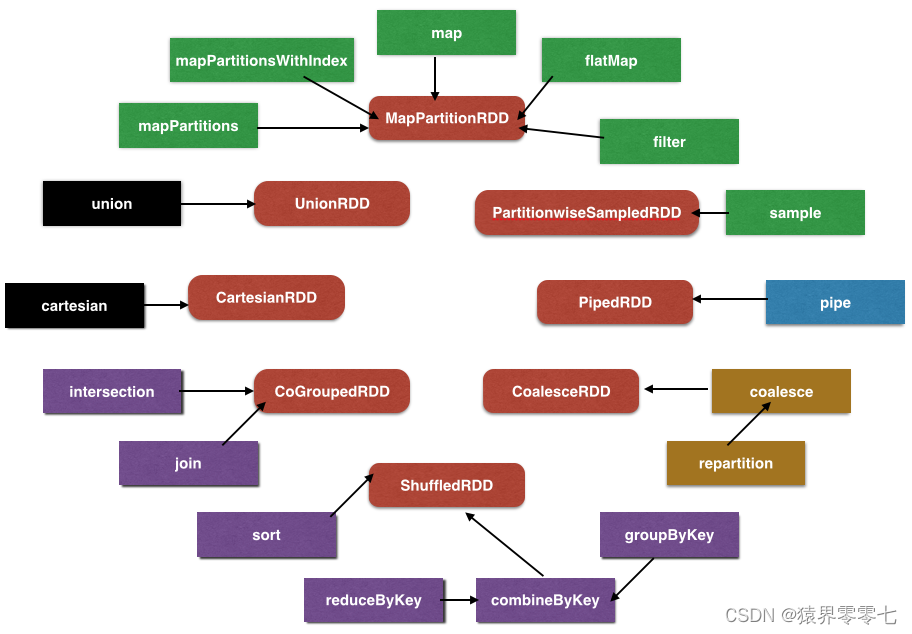
Spark RDD的转换
按颜色区分转换:
绿色是单 RDD 窄依赖转换黑色是多 RDD 窄依赖转换紫色是 KV 洗牌型转换黄色是重分区转换蓝色是特例的转换
单 RDD 窄依赖转换
MapPartitionRDD
这个 RDD 在第一次分析中已经分析过。简单复述一下:
依赖列表:一个窄依赖&…

RDD原理(Spark)
/ 什么是 RDD? /
传统的 MapReduce 虽然具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是在迭代计算式的时候,要进行大量的磁盘 IO 操作,而 RDD 正是解决这一缺点的抽象方法。RDD(Resilient Distributed Da…

Spark学习笔记(二):RDD常用操作
RDD(Resilient Distributed Datasets)是Spark最重要的元件之一,对数据的任何操作都离不开RDD。 RDD分为两种:Transformations(转换操作)和Actions(行动操作), 并且Spark有个惰性机制:…

Spark编程实验二:RDD编程初级实践
目录
一、目的与要求
二、实验内容
三、实验步骤
1、pyspark交互式编程
2、编写独立应用程序实现数据去重
3、编写独立应用程序实现求平均值问题
4、三个综合实例
四、结果分析与实验体会 一、目的与要求
1、熟悉Spark的RDD基本操作及键值对操作; 2、熟悉使…
Spark面试整理-Spark如何处理大数据
Apache Spark处理大数据的能力归功于其设计和架构的几个关键方面。以下是Spark处理大数据时采用的主要方法和技术: 1. 分布式计算 集群部署:Spark可以在多个节点组成的集群上运行,这些节点可以是物理服务器或虚拟机。并行处理:数据和计算任务在集群中的多个节点之间分布和并…

横扫Spark之 - RDD(Resilient Distributed Dataset)弹性分布式数据集
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 一、概念二、理解1. 弹性2. 分布式3. 数据集 三、5个主要特性1. 一个分区列表2. 作用在每个分区上的计算函数3. 一个和其他RDD的依赖列表4. 一个分区器(可选)5. 计…
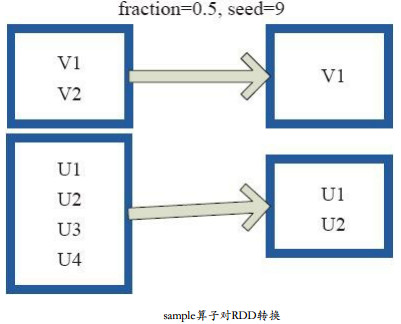
RDD Transformation —— sample
原理
sample将RDD这个集合内的元素进行采样,获取所有元素的子集。用户可以设定是否有放回的抽样、百分比、随机种子,进而决定采样方式。 参数说明: withReplacementtrue, 表示有放回的抽样; withReplacementfalse&a…

Spark RDD Lazy Evaluation的特性及作用
看一些博客都是轻描淡写的说一下这是spark的特性,延迟/惰性计算(lazy evaluation)就完事了,然后各个博客之间抄来抄去就是那么几句话,所以就想着把这些东西整理一下讲清楚,希望对有需要的朋友有所帮助。 主要为了解决3个疑问
rdd…